
Using ASR Web API
The image below shows data flow when using the ASR Web API
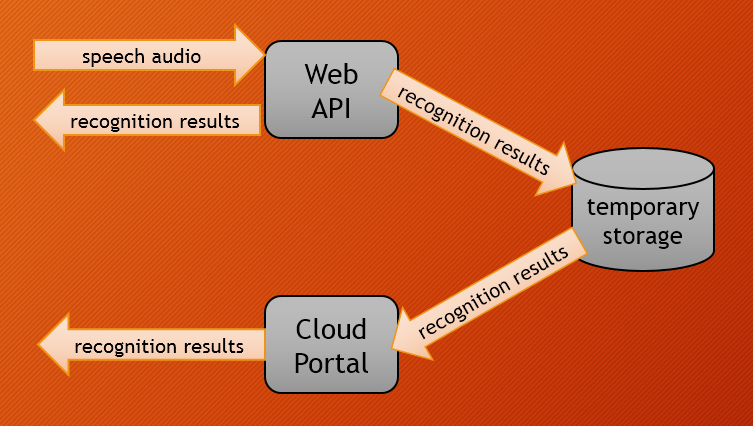
Input speech audio is processed by the ASR engine behind the Web API but the audio data is not stored on the system after the recognition is complete. VoiceGain does not capture and/or use customer audio data beyond what is necessary to return the ASR result.
When making a Web API request, customer has an option to request the result data to be persisted in a temporary cloud storage for a limited time. Such data can then be retrieved via: a) API poll request, or b) via the Web Console. After specified time, the results in storage will expire and no longer be available.
OnPrem Training of Acoustic Models
The image below shows flow of various data as part of the Acoustic Model Training process in an OnPrem install.

In an OnPrem setup, Customer is responsible for provisioning Local Object Storage (there is an option to provision it on the Customer Kubernetes Cluster automatically, however, for maximum reliability and control over data, we suggest use of own provisioned Object Storage).
The Data Flow
Here are the basic steps of training an Acoustic Model:
- Customer uploads the training files (audio + text) to a predefined bucket in their own object storage.
- Training Pre-processor Job running on Customer Kubernetes Cluster processes all uploaded data and generates files suitable for training Acoustic Model. The Processed data is uploaded back to the same customer Object Store but to a different bucket.
- Once pre-processing is complete, the Acoustic Model Training commences. The input to training consists of:
- VoiceGain Base Model - downloaded from Cloud
- VoiceGain Base Set - also downloaded from Cloud. The reason model and base set are separated is to avoid large transfers in subsequent training. Data is being cached on the Kubernetes Cluster to avoid unnecessary transfers.
- Customer pre-processed training sets.
- Once Training is complete the Custom Trained Acoustic Model is uploaded to Customer Object Storage and can later be use for runtime ASR.
Data Ownership and Licensing
- Customer Training Set - Customer fully owns this data. VoiceGain has no rights to this data. Data will be processed by VoiceGain software on the Customer Kubernetes cluster in order to generate Processed Training Data. Apart from that no use of Training Set is made by VoiceGain.
- Customer Processed Training Data & Custom Trained Model - these are similar in that VoiceGain has no rights to them. They will be used by VoiceGain software on the Customer Kubernetes cluster in order to generate new models and for ASR runtime.
The customer has an exclusive license to use these on VoiceGain platform as long as as they remain VoiceGain customer.
The customer is not granted a license to use them outside VoiceGain platform, nor a license to reverse engineer them in any way. - VoiceGain Base Model & Base Set - These are used to train the custom Acoustic Model. Even though they are copied to customer Kubernetes Cluster, the customer has no rights to them beyond that of the VoiceGain software license.
Specifically, the customer is prohibited from copying these outside the Customer Kubernetes Cluster. Also prohibited are any attempts to reverse engineer both.
Comments
0 comments
Please sign in to leave a comment.