
High-Level Concepts
- Question : question prompt sets the context for the experiment. It determines the utterances that are expected. For example, a question "Is your bill late?" will elicit "yes" and "no" responses, but also responses like "yes, my bill is late" or "no, I already got my bill". The Experiments are organized by question.
- Audio Set : Set of utterances to be processed. It is best to use a test set of between one hundred utterance to several thousand utterances. A too small set will give unreliable statistics, and a too big audio set will be difficult to thoroughly review.
- Grammar : Grammar, e.g. GRXML, that is used to recognize utterances.
- Experiment : Results of experiments can be compared, analyzed, and visualized using the GREG Web UI. An experiment comprises the following:
- Question: this sets the context for the experiment
- Set of input utterances - these have to be reviewed using GREG to assign true values of utterance and semantic ??
- Grammar that is used.
- Recognition result - utterances, interpretations, and confidence
Data can be fed to an Experiment in 2 ways:
- Uploaded via Web UI - see here how to do this.
- Collected from a live IVR - grammars would be instrumented with metadata indicating to which Experiment the recognition results should be uploads
- (Coming Soon) Telephony Bot API will be able to submit recognition results to GREG
Glossary
- GREG : Originally it stood for Grammar REGression, however, now you can also test performance of various NN Models and ASR settings.
- ASR : Automated Speech Recognition
- OOG : Out Of Grammar - real spoken utterance is outside of the set of utterances generate/recognized by the grammar. It is impossible to recognize this utterance using the grammar.
- IG - In Grammar : real spoken utterance falls within the grammar, i.e. it can be recognized by the grammar. If it does not get recognized it is because the ASR had problem with the way it was said, noise, volume, audio quality, etc.
- NM - NOMATCH : ASR could not recognize the spoken utterance either due to it being OOG or ASR model not able to generate hypothesis.
- Note: sometimes we will instrument grammar to return __garbage__ interpretation for matched utterances that the IVR logic would not be able to handle. These are treated as if we had a NOMATCH.
- TN - True Negative (Correct Rejection) : OOG utterance was correctly not recognized
- FP - False(ly) Positive (False Alarm) : OOG utterance was incorrectly recognized as some in-grammar utterance
- N = TN + FP : Negative Outcomes
- TP - True Positive (Hit) : In-Grammar utterance was correctly recognized
- WP - Wrong Positive (misclassified) : In-Grammar utterance was recognized wrongly as some other In-Grammar utterance
- FN - False Negative (Miss) : In-Grammar utterance was rejected - this can have several causes:
- there was No Match
- utterance was given __garbage__ tag by the grammar
- confidence of recognition was below acceptance threshold
- P = TP + WP + FN : Positive Outcomes
- Precision = TP / (TP + WP + FP) : https://en.wikipedia.org/wiki/Precision_and_recall#Precision
- Recall = TP / P : https://en.wikipedia.org/wiki/Precision_and_recall#Recall
- Accuracy (A) = (TP + TN) / (P + N) : https://en.wikipedia.org/wiki/Accuracy_and_precision#In_binary_classification
- F1 score (F) = 2*P*R / (P+R) [a harmonic mean of Precision and Recall] : https://en.wikipedia.org/wiki/Precision_and_recall#F-measure
- Total Error = (FP + WP + FN) / (P + N)
Table of Outcomes
| True Classification | Positive / Negative | Recognizer Outcome | Outcome Category if below or equal threshold |
Outcome Category if above threshold |
| OOG | N | OOG or NM | TN | TN |
| OOG | N | IG (always incorrect) |
TN | FP (OOG has been accepted as IG) |
| IG | P | OOG or NM | FN | FN |
| IG | P | IG incorrect | FN | WP (IG has been misclassified) |
| IG | P | IG correct | FN | TP |
If threshold is 0 (min) we have the following categories:
- Out of Negative
- TN : this will be the lowest possible TN value
- FP (all OOG that are recognized as IG) : this will be the highest possible FP value
- Out of Positive
- TP : highest possible TP value
- WP - highest possible WP value
- FN (if classified as OOG/NM) : lowest possible FN value
If threshold is 100 (max) the we will have only:
- Out of Negative:
- TN
- Out of Positive:
- FN
Charts
Total Operating Characteristics
You can learn more about this type of chart from this wikipedia article: https://en.wikipedia.org/wiki/Total_operating_characteristic
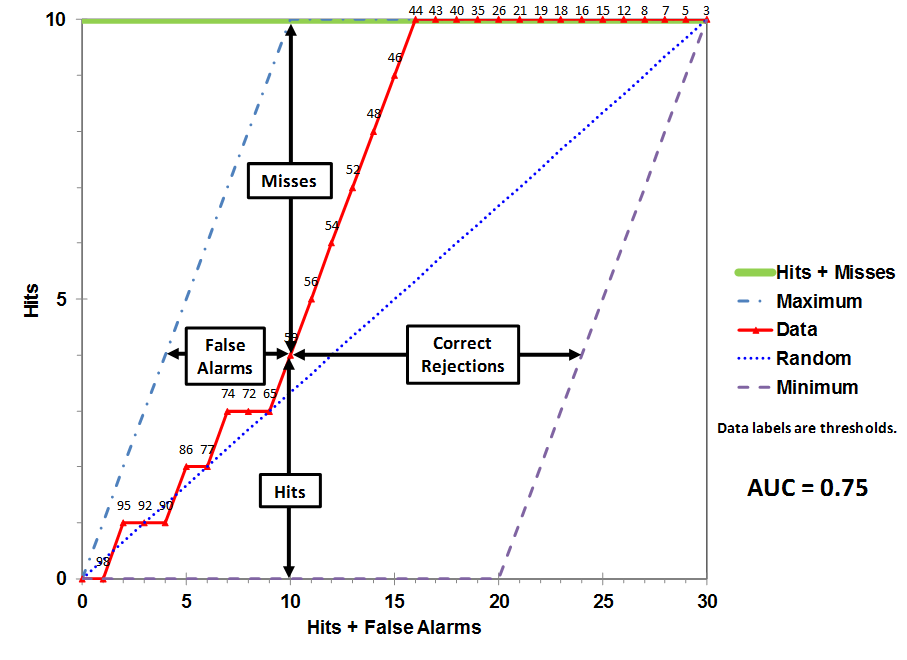
Mapping of the terminology from the wikipedia to the terminology use by us is as follows (Wiki -> us):
- False Alarm -> False Positive (FP)
- Hit -> True Positive (TP)
- Miss -> False Negative (FN)
- Correct Rejection -> True Negative (TN)
In our chart we are additionally adding Wrong Positive between Hit and Miss
Comments
0 comments
Please sign in to leave a comment.